 JPA - guideline
JPA - guideline
Это конспект-выдержка из различных книг, лекций и статей, чтобы наконец структурировать материал в чертогах разума.
Итак, JPA с Hibernate, ORM, JDBC, Spring Data JDBC/JPA - почему возникли и для чего их так много? Разложим же ментальные бумаги по их стопкам:
Предыстория и проблематика
Долговременное хранение данных в программных проектах обычно осуществляется (опустим NoSQL и их частоту появления в проектах) с помощью реляционных баз данных или RDBMS (Relational DataBase Management System - сокр. РСУБД, система управления реляционными базами данных). Здесь (Relational DataBase Management System) - Management System - потому что это программное обеспечение, которое обеспечивает взаимодействие разных внешних программ с данными и дополнительные службы (журналирование, восстановление, резервное копирование и тому подобное), в том числе посредством SQL. То есть программная прослойка между данными и внешними программами с ними работающими А Relational - потому что хранит данные в виде таблиц (“отношений”): храним данные в табличной структуре, соединяющей связанные по какому-то принципу элементы данных:
Таблица “Утки”
Где каждая запись - строчка, поля записей - столбцы, значения поля одной записи - ячейка на пересечении строчки и столбца.
Создание таких таблиц, доступ к их данным и их модификация осуществляется с помощью языка запросов SQL (Structured Query Language). Кстати, там есть подразделения языка на
сделать таблицу
- DDL (Data Definition Language, например, запрос CREATE)
- DML (Data Manipulation Language, например, INSERT)
- DCL (Data Control Language, например, GRANT)
- TCL (Transactional Control Language, например, COMMIT)
- DQL (Data Query Language, где, собственно, один запрос SELECT. Иногда относят к DML)
- PL (Procedural Language, например, команда IF) да, несмотря на то, что SQL - декларативный язык, там все равно понадобилось программирование
Итак, управляем данными в базах с помощью команд декларативного языка SQL "CREATE TABLE DUCKS", а пишем собственно? В .. SQL клиентов ()?
JDBC
Для Java-приложения также появилась технология доступа к базе данных - JDBC (Java DataBase Connectivity). Она появилась почти через год после анонса языка и ее пакет (java.sql, потом это был javax.sql, сейчас jakarta.sql) является стандартным для Java и входит в Java SE. Для Java появился драйвер, позволяющий подключаться к базе и чтобы писать запросы к ней
Драйвер предоставляется разработчиками баз данных и добавляется в зависимости проекта (в Spring Boot как всегда из коробки)
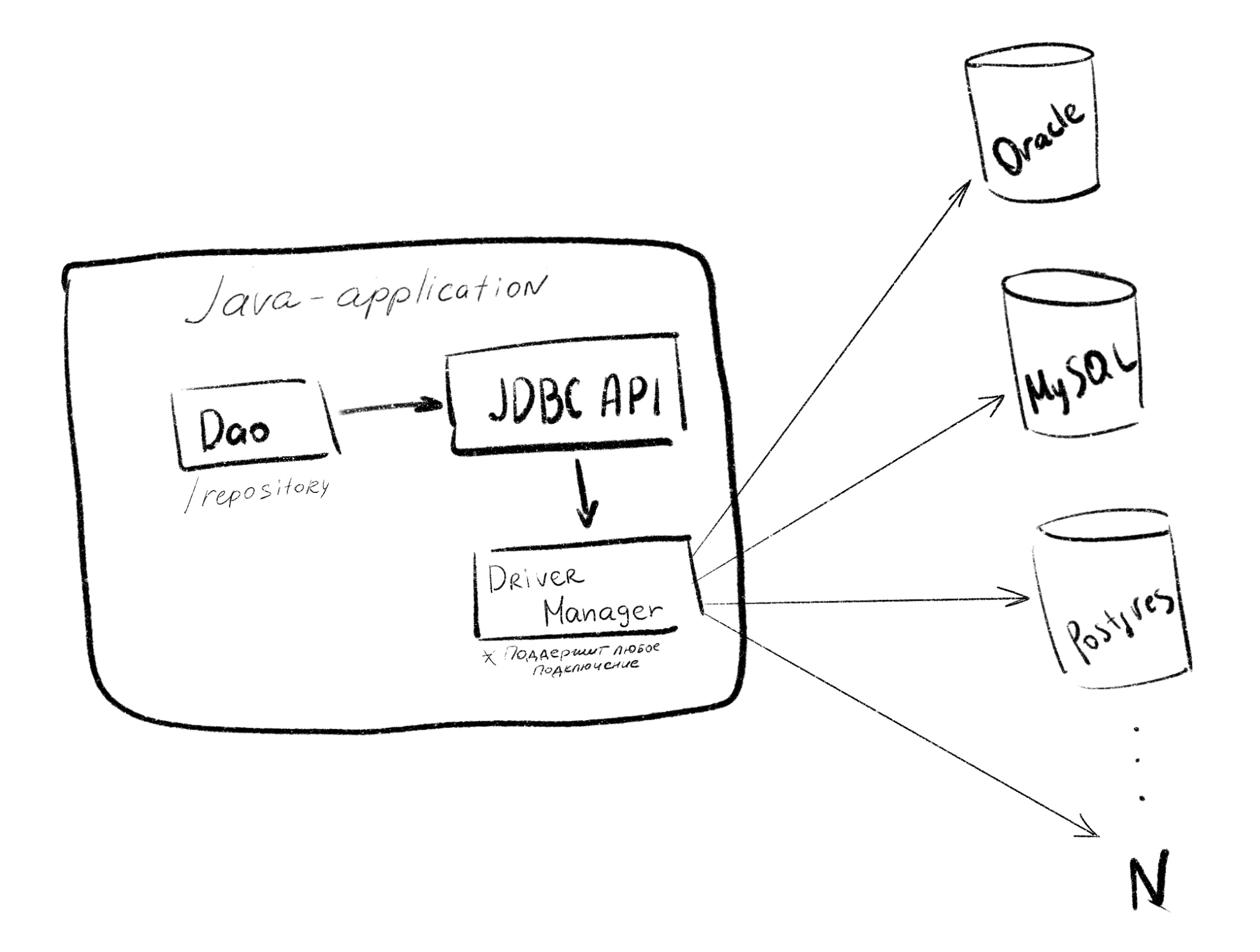
Как работает JDBC
Пишем один и тот же JDBC код (одними и те ми же методами), но разными SQL (например, у Postgres’a некоторые запросы могут отличаться от vanilla SQL у Oracle) JDBC под капотом использует Driver-manager
собственно, ему же и прописываем доступ
private Connection getNewConnection() throws SQLException {
String url = "jdbc:h2:mem:test";
String user = "sa";
String passwd = "sa";
return DriverManager.getConnection(url, user, passwd);
}Plain JDBC и Spring JDBC:
Statement
ResultSet
RowSet
И вроде бы можно было бы хорошо жить и поживать с JDBC, но зачем-то придумывают ORM (Object-Relational Mapping). Зачем? Допустим, у нас есть таблицы и между ними связи, и наше приложение с ними вовсю взаимодействует (CRUD’ы и прочее):
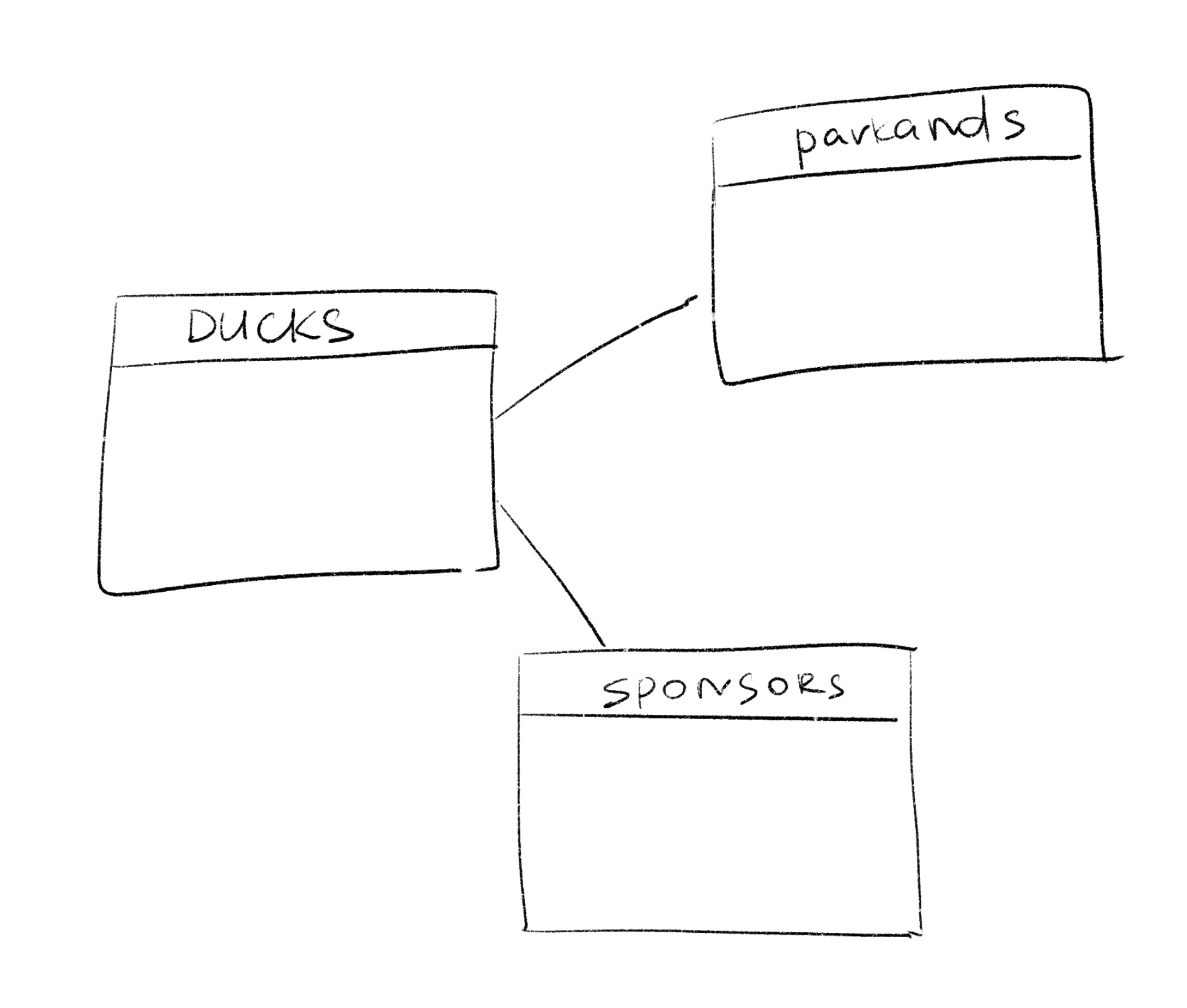
И, хорошо, если проект небольшой, с парой-тройкой бизнес-моделей, но что если таких моделей много больше? (даже в рамках микросервиса)
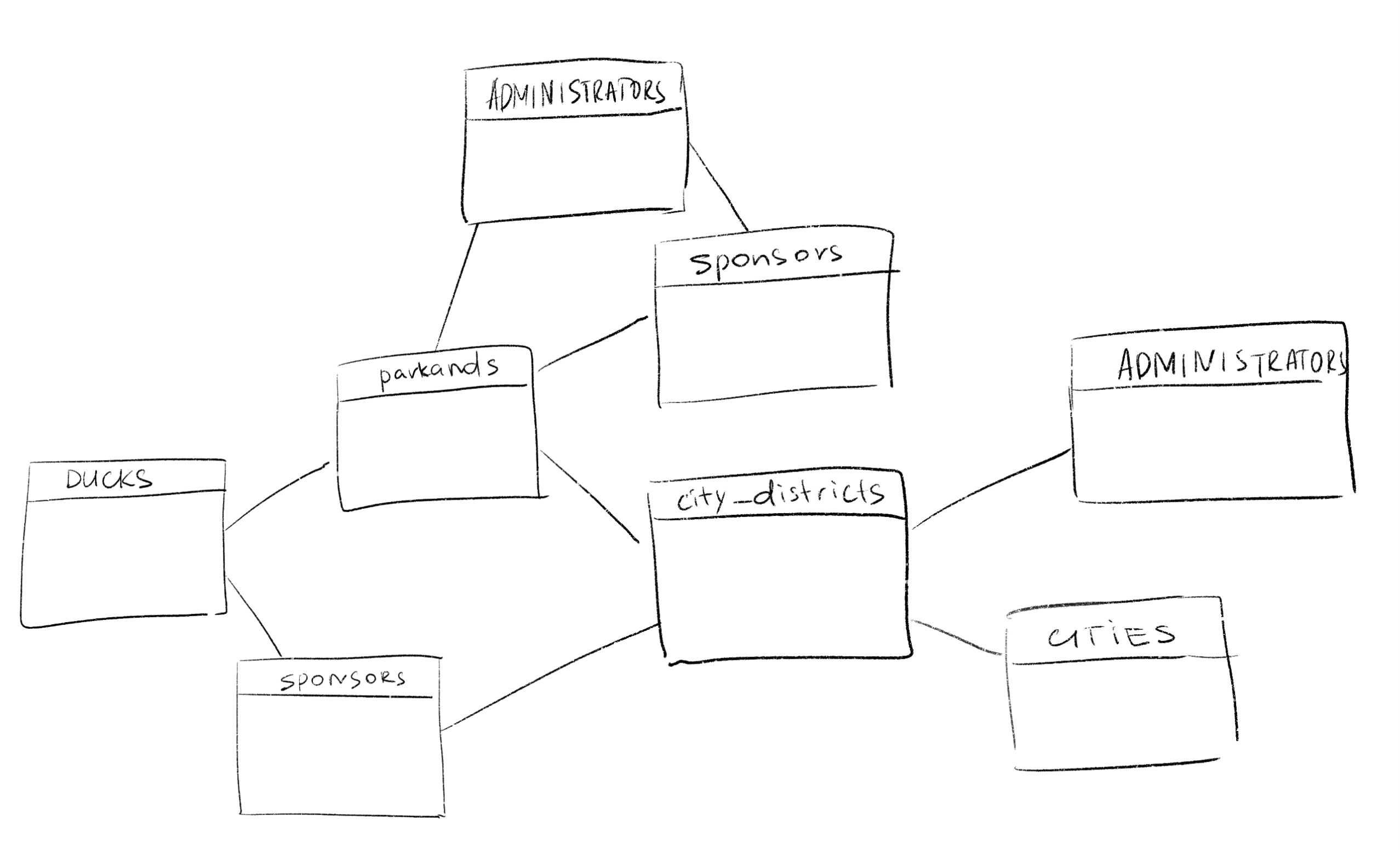
Кольца смерти
Таким образом мы получаем примерно такое полотно запроса:
и это только чтобы достать один объект со связями. А если у нас таких сотни? Это достаточно много строк кода, даже с немногословным JDBC
http://spring-projects.ru/projects/spring-data/
И вот тут нам нужен другой подход:
Определение ORM и JPA
Вместо этих манипуляций ORM-подход предлагает использовать представлять таблицу в объект, отсюда и название подхода: Object-Relational Mapping, то есть (от слова map, сопоставлять) сопоставляем нашему Java-объекту - DB-объект
Jakarta Persistence API (которая раньше была **Java Persistence API) это API-спецификация, реализация пакета jakarta (persistence - здесь в значении “неизменный”)
Все библиотеки, как всегда, подключены в spring-boot-parent из коробки.
Кстати, есть такая книга - Правила выживания в Джакарте 🏝️
JPA представляет собой аннотации, И вот Hibernate как раз является одной из реализаций спецификации JPA.
Понятие Entity

@Column (insertable=false, updatable=false)
Вместе с Jakarta появляется еще одна стратегия генерации
Plain JPA и Spring JPA: Отличие от Spring Data JPA Spring Data JPA - это один из «подпроектов» проекта Spring Data.
- Spring Data можно использовать без Hibernate, но сам по себе Spring Data не умеет преобразовывать объекты в структуры данных БД.
Entity Manager
Когда мы работаем с EntityManager - по сути, мы создаем Session, создается сессия для работы с базой и создается такая вещь как PersistanceContext https://www.baeldung.com/jpa-entities-serializable
Criteria API https://www.bychkov.name/java-ee-tutorial/persistence-criteria003.html
Specification https://habr.com/ru/companies/rshb/articles/521220/ Query DSL
JPQL
https://spring.io/blog/2011/04/26/advanced-spring-data-jpa-specifications-and-querydsl
Собственно ссылки на эти различные книги, лекции и статьи:
https://javarush.com/groups/posts/1952-vvedenie-v-sql
Как устроены базы данных. Highload Junior Spring Data JDBC Андрей Беляев